
Internally we use Log4j2 as our logging solution of choice (with the various off-the-shelf adapters to handle 3rd libraries with different log frameworks). An interesting aspect of our internal test infrastructure is that we do capture all trace logs during test runs (including HTTP requests, headers, generated test data, etc.) but only for the lifetime of a test run. If a test passes, we ignore the logs. If the test fails (or is a flake), we’ll actually send the log to the next configured appender (usually a Console or RollingFileAppender).
One test started failing rather consistently after we recently changed some of our logging infrastructure and configuration. That test was using one of our components to connect to a server, post some data, retrieve the data and assert that the new data is present. In other words, it was doing some HTTP requests, parsed the data and asserted on that.
This represents a rather boring yet important end-to-end test. We run a lot of similar tests against myriad servers and even more versions of the aforementioned. Under regular circumstances, the test passed. The fun part started when running the test with trace logging enabled. Enabling trace logging, the tests started to fail pretty consistently … With a NoHttpResponseException…And always the same URL.

After Holger briefly described the situation, it was pretty clear to me that my coding skills were still on vacation as this analysis made absolutely no sense. Even worse, one approach to “fix it” was to limit the size of the logs to a few kilobytes (don’t ask how we got to that point). That made the test pass and the HTTP request to succeed.
At that point, it had to be something that is logged which is causing the problems. Maybe some encoding issue? Are we somehow hitting some edge case with certain unicode characters coming from the server?
It wouldn’t be the first time this happens to us; years back, we had fun working with an API that stalled the server for 2-3 minutes if you used any unicode character in your requests – but that’s a story for another day.
With the knowledge that it had something to do with how large the logs are, we started digging deeper. To better isolate the problem and reduce the number of things that could possibly contribute to this, we ran the tests again and piped all requests into separate files. This allowed us to try and replay the scenario to see if those requests (which were quite large) had anything specific to them.
$ du -sh *.log | sort
2.0M request-11.log
2.0M request-8.log
384K request-10.log
384K request-12.log
384K request-3.log
384K request-7.log
496K request-1.log
496K request-13.log
496K request-2.log
496K request-4.log
496K request-5.log
496K request-6.log
496K request-9.log
Interesting enough, we have some outliers here with 2MB for each response from the server. Taking a closer look reveals that these are mostly XML documents (or SOAP envelopes to be specific). While 2 megabytes is a lot of bandwidth, it’s not too uncommon for SOAP-based web services.
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<soapenv:Body>
<queryWorkItemsResponse xmlns="">
<ns4:queryWorkItemsReturn uri="subterra:data-service:objects:/default/ABC${WorkItem}ABC-22908" unresolvable="false">....
While digging into these things, we had one related observation. The tests in question, while usually taking some time to run, actually took a lot longer when running with trace logging enabled (and failed). It’s not that trace logging comes for free but Log4j2 (like most other logging frameworks noways) is designed to be extremely fast and even garbage-free. Just to put out suspicion to rest, let’s write a very simple test case. Take the responses that we just captured and log them (to simulate what we do in our real scenario).
public class Reproducer {
private final Logger logger = LogManager.getLogger(Reproducer.class);
@Test
public void logCapturedServerResponse() throws Exception {
File logFile = ...;
String log = Files.toString(logFile, Charsets.UTF_8);
logger.trace(log);
}
}
Using a 2MB http response file from above, this test runs for 50s on a decent MacBook.

Time to start Yourkit and figure out what exactly is taking us 50s to log a large string. Running the test using the profiler reveals something very interesting.
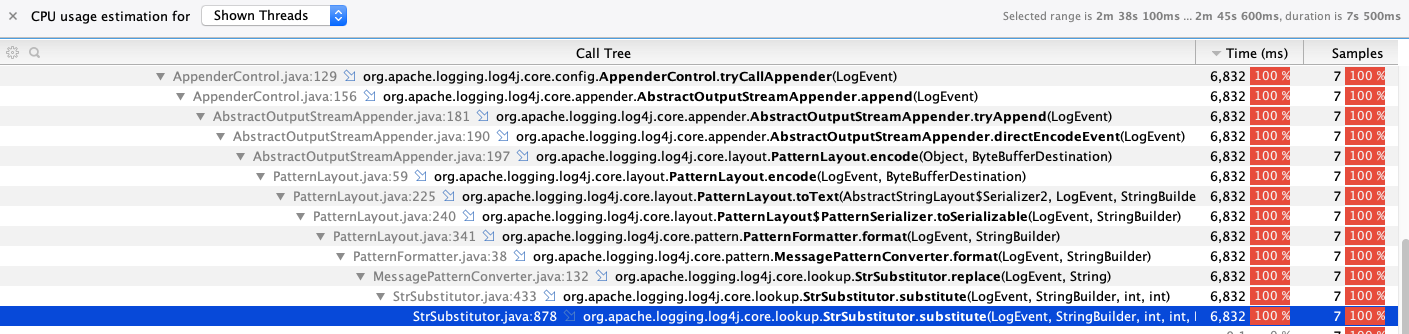
Log4j2 is performing a lot of string substitutions for the pattern layout used by the logs. That is…surprising. While we use a little bit of a more verbose format, it’s nothing too controversial. The pattern we use is %c{3} - %m%n.
As stated on the Layouts documentation
- %c – Outputs the name of the logger that published the logging event.
- %m – Outputs the application supplied message associated with the logging event.
- %n – Outputs the platform dependent line separator character or characters.
Caution: There are some placeholders that actually do require expensive operations (e.g. %M to log the method name of the callee) but none of the was used in this. See Location information to learn about those patterns.
So we have established that our pattern for logging is quite trivial. We even tried using just %m with no resolution, the test still took about 1 minute to run. While digging into the offending StrSubstitutor class (which is just a fork of the commons-lang StrSubstitutor), there was an interesting bit that caught our eye in the JavaDoc.
Variable replacement works in a recursive way. Thus, if a variable value contains a variable then that variable will also be replaced.
Huh. Could it be that the responses from the server may actually contain something that log4j2 would recognize as a variable? A quick look at the response gives us the shocking answer. Not only once or twice but some of those SOAP responses contain more than 3000 occurrences of ${Project} or ${WorkItem}.
<ns8:queryWorkItemsReturn uri="subterra:data-service:objects:/default/ABC${WorkItem}ABC-22904" unresolvable="false">
This provoked log4j2 to parse the 2MB responses and replace the “variables” which in turn led to the server closing the connection on us in between.
To be honest, while you can argue about the format and use case, this API decided to use this format represent certain URIs. That Log4j2 is trying to actually interpret the placeholders in values passed in is the (at least to us) the surprising part.
Good for us, log4j2 already provides a flag on the %m placeholder to disable recursive variable substitution. From their documentation:
Outputs the application supplied message associated with the logging event. Use {nolookups} to log messages like “${date:YYYY-MM-dd}” without using any lookups. Normally calling logger.info(“Try ${date:YYYY-MM-dd}“) would replace the date template ${date:YYYY-MM-dd} with an actual date. Using nolookups disables this feature and logs the message string untouched.
Using the pattern $m{nolookups}%n now only takes half a second to trace log the message.
Fazit
Having recursive lookups enabled by default is an interesting choice as it may start to slow down your performance unnecessarily if you don’t make use of this feature. But more importantly, this is something to watch out for when it comes to log forgery/log injection depending on how you consume the log files. Let me know if you experienced similar behaviors and how you worked those out.




